


Ein Teil unserer Mission innerhalb von Core AI bei eBay ist die Entwicklung von Computer-Vision-Modellen, die innovative und überzeugende Kundenerlebnisse ermöglichen. Aber wie können wir verschiedene visuelle Suchmodelle vergleichen und sagen, welches von ihnen besser funktioniert? In diesem Artikel wird eine Methode beschrieben, die dieses Problem direkt aus den Augen der Benutzer angeht.
Die Bildsuche ist eines unserer zentralen Produkte. Die Benutzererfahrung hat sich von der textuellen Suche zur visuellen Suche verlagert, bei der ein Benutzer entweder ein Live-Bild aufnehmen oder ein Bild von seinem Gerät auswählen kann.
Durch den Einsatz von faltenden neuronalen Netzen sind wir in der Lage, Bilder zu verarbeiten und dann ähnliche Live-eBay-Angebote zu finden, die wir einem Benutzer vorschlagen können. Diese vorgeschlagenen Angebote werden auf der Grundlage ihrer Ähnlichkeit in eine Rangfolge gebracht und dann dem Benutzer angezeigt. Während wir diese Modelle trainieren, stehen wir vor der Herausforderung, ihre Leistungen zu bewerten. Wie können wir mehrere visuelle Suchmodelle vergleichen und sagen, welches von ihnen besser funktioniert?
Da unser Hauptziel darin besteht, überzeugende Kundenerlebnisse zu schaffen, wird in diesem Artikel eine Methode beschrieben, die dieses Problem direkt aus den Augen der Benutzer angeht.
Vorbereitung des Datensatzes für die Auswertung
Wir verwenden einen festen Satz von n nach dem Zufallsprinzip ausgewählten, vom Benutzer geladenen Bildern, die während dieser Auswertung als unsere Abfragebilder für beide Modelle dienen werden.
Diese Bilder waren nicht Teil des Schulungssets, das aus den aktiven Angeboten von eBay besteht, sondern spiegeln die wahren Bilder wider, die unsere Käufer bei der Suche nach eBay-Produkten verwenden. Für jede Suchanfrage (d.h. für ein Ankerbild) rufen wir ein Modell auf, erhalten die 10 besten Ergebnisse pro Ankerbild und sammeln dann 10Xn Bilder pro Modell, die für unseren Evaluationsdatensatz ausgegeben werden.
Hinzufügen des Menschen in die Schleife
Sobald wir den Auswertungsdatensatz haben, laden wir diese Bilder in FigureEight (d.h. Crowdflower) hoch, eine Crowd-Tagging-Plattform, die wir verwenden, um Antworten darauf zu sammeln, wie gut die Ausgabe eines Modells im Vergleich zum gegebenen Ankerbild ist (siehe Abbildung 1).
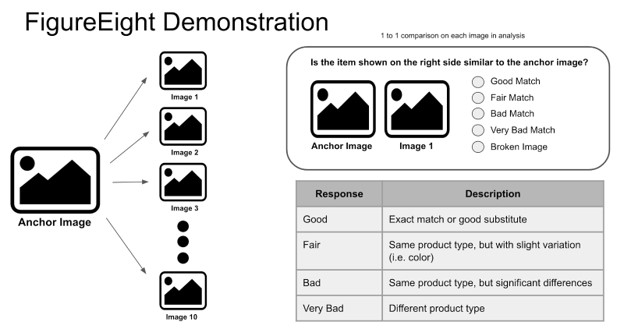
Da die Beurteilung von Bildern extrem subjektiv ist, haben wir uns entschieden, dynamische Beurteilungen einzubeziehen, um für jedes befragte Bildpaar einen Vertrauenswert zu ermitteln. Wir beginnen damit, dass wir drei Personen die gleiche Frage stellen und ihre Antworten überprüfen. Wenn sie alle die gleiche Antwort geben, behalten wir diese Antwort. Wenn sie unterschiedlich antworten, werden wir zwei weitere Personen (insgesamt bis zu fünf) befragen, um ein hohes Vertrauen in diese Antwort zu gewährleisten.
Unsere Evaluatoren werden während der Beantwortung dieser Fragen ebenfalls getestet. Es gibt Testfragen, die von unserem Team handverlesen werden und die jeder Evaluator durchlaufen muss, um sich als gültiger Etikettierer zu qualifizieren. Ihre Genauigkeit bei diesen Testfragen wird mit ihrem Vertrauenswert verknüpft. Sie müssen bei dem Test mindestens 70 % erreichen, um für diese Aufgabe akzeptiert zu werden. Zusätzlich zum Vortest gibt es über die gesamte Aufgabe verteilte Testfragen, die dazu führen könnten, dass ihr Vertrauenswert unter den von uns festgelegten Schwellenwert von 0,7 fällt, was zur Folge hätte, dass diese Kennzeichner von der Aufgabe entfernt würden.
Die Gesamtvertrauenspunktzahl für jede Antwort wird durch den Grad der Übereinstimmung zwischen den Kennzeichnern und dem ihnen zugewiesenen Vertrauensniveau berechnet.
Wenn zum Beispiel zwei Arten von Antworten für dieselbe Frage ausgewählt wurden, nehmen wir die Antwort, die insgesamt einen höheren Vertrauenswert hat. Es werden nur Fragen bewertet, die ein Vertrauen größer oder gleich 70 % haben (siehe Abbildung 2).
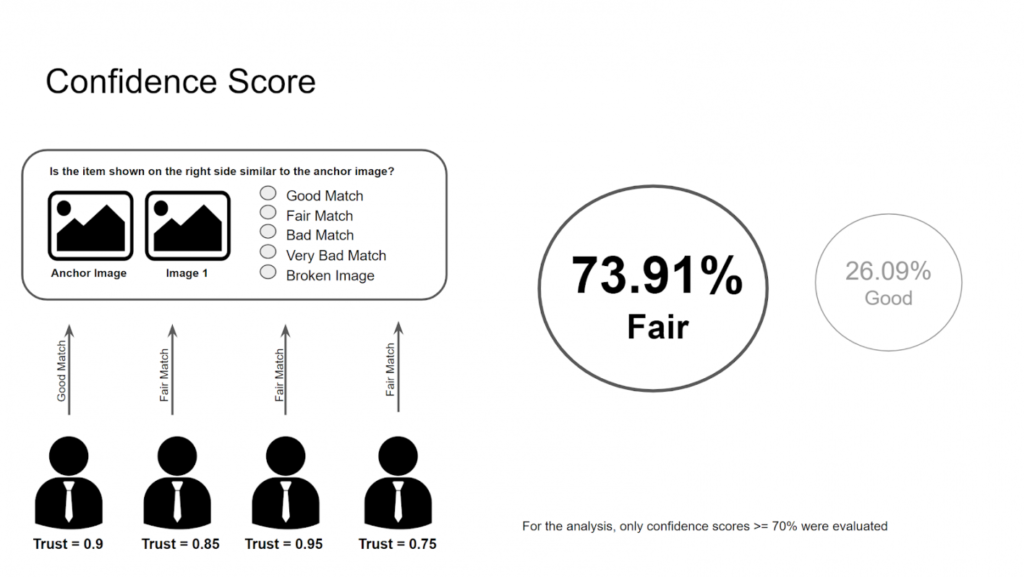
Berechnung der Gesamtpunktzahl pro Modell
Dieser Prozess wird durchgeführt, um für jedes der von uns evaluierten Modelle eine Punktzahl zu erhalten, so dass wir eine faire Bewertung zwischen den Modellen vornehmen und entscheiden können, welches von den Nutzern bevorzugt wird. Wir verwenden DCG (Discounted Cumulative Gain), das eine Standardmetrik für Ranglistenergebnisse ist (siehe Abbildung 3).
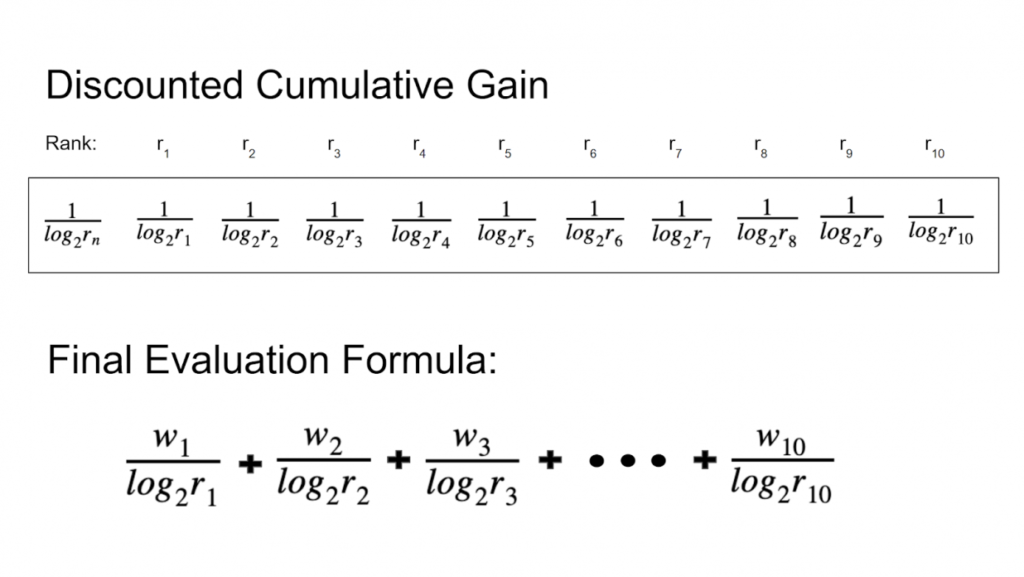
Die von uns verwendeten Gewichte sind in der folgenden Tabelle beschrieben.

Sobald wir alle Antworten aus der Menge haben, können wir der Formel die entsprechenden Zahlen zuweisen und die Gesamtpunktzahl für jedes Modell akkumulieren. Ein Modell mit einer höheren Punktzahl bedeutet ein Modell, das mehr relevante Suchergebnisse pro diesem 10Xn-Bewertungssatz lieferte und somit das ausgewählte Modell sein wird.
(Quelle: eBay Tech Blog von: Michal Romi, Michael Ebin and Chantal Acacio; Übersetzt mit deepl.com)








{kind=link}